用AI帮我自动翻译博客文章
开发了一个npm库,可以调用大模型批量化翻译博客。告别博客的语言壁垒!
起因是因为本人写博客喜欢英文和中文换着写,这样以来有些读者读起来会比较吃力,所以就想用一个自动翻译来把博文翻译成另外一种语言。还有一个原因是我在设计这个博客网站的初期专门做了日文字体的适配(虽然自己只懂一点点日文)但想着做都做了,还是有日语版比较好。
现有的翻译博客方法
翻译软件。这种方法就是把文章一段一段的放进Google Translate进行翻译然后再粘到一个新的markdown文档中。也有自动化的方案比如auto-i18n。这种方法的一大弊端就是机器翻译的非常僵硬,有些术语也会解释错误。但好处就是便宜和快速。
人工翻译。顾名思义就是写完一种语言再用另外一种语言重写一遍,准确是挺准确的,流畅度也能得到改善,但是就是有点费人。
AI翻译。到了2026年,大语言模型可以说是比较成熟了。对于翻译这种纯文字的工作应该是轻而易举就能胜任了。把博客文章贴到prompt栏里去,让模型去翻译,既省时间有有了准确度,是一个非常不错的选择。
不过用人来一篇一篇的去黏贴,最后再粘回来也有点繁琐。那就写个脚本去自动化吧!
设想
这个项目的目标就是将已有的博客文章(md也好,mdx也好),通过调用大模型的API接口(openai compatible),让他来帮我翻译成我想要的语言,输出到相应语言的目录下。
最后的输出差不多长这样:
content/
post1.md
post2.md
en/
post1.md
post2.md
jp/
post1.md
post2.md
汇总下来需要有两个主要的功能:
- 翻译单个文章
- 批量翻译一整个目录下的文章。
最后就是支持要cli,能够在博客编译前自动执行。
具体实现
翻译方案
这是我第一次开发一个npm的库,所以我也不知道怎么弄,所以直接请出我们的ChatGPT进行规划。

GPT的想法是先把markdown文档parse成AST(Markdown Abstract Syntax Tree,具体可以参考这篇文章),然后再逐段进行翻译。把每一段算一个hash,以后改的话hash变了就从新翻译。
这里有两个问题,
- 逐段进行翻译就意味着要牺牲上下文的连贯性来确保md语法格式不变,即使增加了上下文的注入,也会难免的产生上下文不协调的情况。当然还有一种方法,就是在翻译之前先让大模型生成一个文章,概要这样子就可以把context传递给大模型。不过本人觉得这样的方法不是特别好写也就放弃了。
- 计算固然是一个很好的方法,但是本人写完了博客大概率就不会改了,要改的话也就那一两篇,完全没有必要去设计这样一个防止重复翻译的机制。
对于为什么GPT不提出直接将整个文章进行翻译的猜测 这个方法的弊端就是一旦文章的长度变长,那么大模型就很有可能会丢失md语法,从而导致最后的编译失败。但好在这个方法足够简单,而且我的博客文章一般不超过2000字所以根本不会exceed大模型的context window,最后就选择了这样的一个方案。
我就按照这个方案写了一个prompt:
You are a translator who works with Markdown files.
Translate the document the user gives you into ${langName}.
Follow these rules:
1. Keep all Markdown formatting the same. Don't change headings, bold, italics, tables, lists, quotes, horizontal lines, etc.
2. Don't change any web links, image paths, or HTML settings.
3. Don't change code blocks or inline code. Only translate comments inside code if they're in the original language.
4. If the text has jokes, idioms, wordplay, or memes that don't make sense if translated directly, rewrite them so they feel natural in ${langName}.
5. Only give the translated Markdown. Don't add explanations, code blocks, or extra information.
模型选择
我一开始是想用ChatGPT的API的,但是后来发现了Qwen有专门翻译的模型(其实是发现Qwen新用户免费送API额度)Qwen-MT系列。这个模型是由Qwen3微调出来的模型,可以指定一个原文本的语言(可设为auto)和要翻译成的语言。由于这个语言的参数不包含在原来的openai的api接口中所以要额外传一个extra_body参数。

这个价格也是十分亲民了(使劲用也不会伤钱包的那种

最后综合模型的各项性能,我选择了qwen-mt-flash。注意这里的lite模型只支持32种语言的翻译,而剩下的都支持92种。具体选型请看下表。
| 模型 | 推荐场景 | 效果 | 速度 | 成本 | 支持的语言 | 支持增量流式输出 |
|---|---|---|---|---|---|---|
| qwen-mt-plus | 专业领域、正式文书、论文、技术报告等对译文质量要求高的场景 | 最好 | 标准 | 较高 | 92种 | 不支持 |
| qwen-mt-flash | 通用首选,适用于网站/App内容、商品描述、日常沟通、博客文章等场景 | 较好 | 较快 | 较低 | 92种 | 支持 |
| qwen-mt-turbo | turbo模型后续不再更新,建议选用效果与功能均更优的flash模型 | 良好 | 较快 | 较低 | 92种 | 不支持 |
| qwen-mt-lite | 实时聊天、弹幕翻译等对延迟敏感的简单场景 | 基础 | 最快 | 最低 | 31种 | 支持 |
配置
这个工具的配置特别简单,只需输入以下命令安装
npm i md-blog-i18n
创建md-blog-i18n.config.json配置文件
对于除qwen-mt系列的模型,填入以下内容
{
"openaiApiKey": "sk-...",
"model": "gpt-4o-mini",
"baseUrl": "https://xxxxxxxx",
}
qwnen-mt模型需要多加入translationOptions的参数
{
"openaiApiKey": "YOUR_DASHSCOPE_API_KEY",
"model": "qwen-mt-flash",
"baseUrl": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"translationOptions": {
"sourceLang": "auto"
}
}
使用
可以直接在cli中调用,格式如下
npx md-blog-i18n <input-dir> <lang1> [lang2 ...]
在开发的过程中,我发现传入qwen-mt模型的targetLang参数不能是简写(比如ja,en这种)只能是完整的语言名称(Japanese),所以还需要在代码中定义一张表来将cli传入简写映射到完整的名称上。
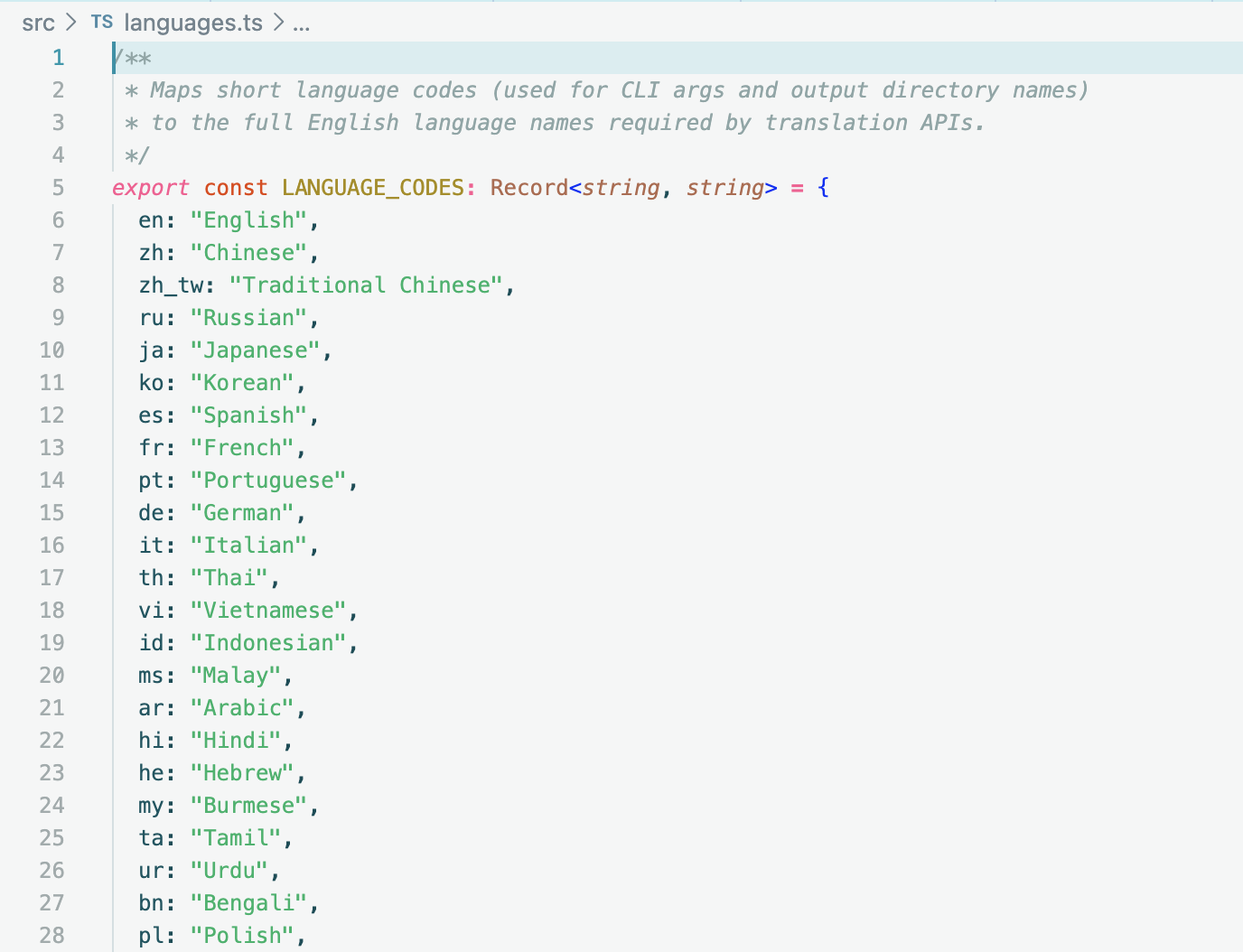
其他更加具体的使用方式可以参考我的github repo
有了这个就可以在packages.json中在编译前运行这个代码,比如
{
"scripts": {
"prebuild": "md-blog-i18n content ja fr zh",
"build": "next build"
}
}
写在最后
这个项目其实还是有很多可以改进的地方的。比如现在还不支持检测哪些文章被翻译过,让程序跳过那些文章。还有增加翻译后sitemap如何处理等等。
尽情期待后续的更新~~~
SHORTLINK
LICENSE
This content © 2025 by Xiaochuan Qian is licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International unless stated otherwise.![]()
![]()
![]()
![]()